Netrasemi focuses on domain specific application performance which is key from a device and edge deployment point of view. Even though our AI performance numbers are comparable or better than our competitors, We provide maximum “Application performance/Power” rather than AI performance numbers. Because, in a realistic edge-AI application usecase on a device, unlike server context, application performance is attached to multi-kernel processing efficiency– for example, for a surveillance application, it is a mix of computer vision, image signal processing, video compression and Neural processing. Here, application performance is achieved by the intelligent mix of hardware kernels working together to achieve the best real-time performance while maintaining power efficiency. This is where domain specific optimisation for the SoC is critical. We focus on delivering the best-in class video analytics and multi-sensor fusion for our targeted usecase.
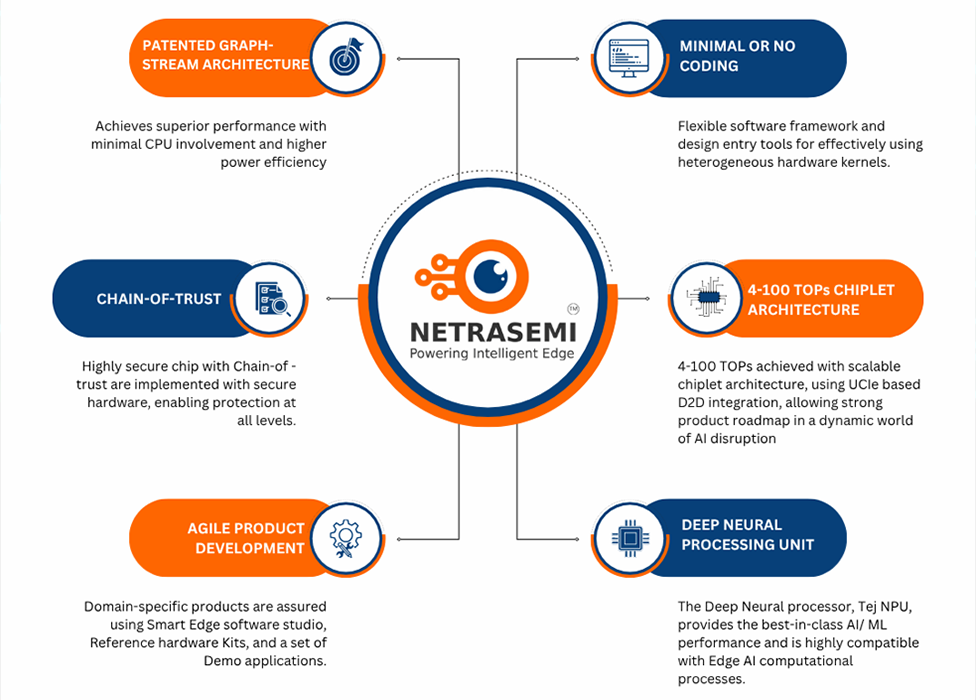
Netrasemi has an extremely energy efficient architecture for vector processing. This architecture defines a graph-like streaming(configurable pipelining) of vector data (in multiple granularities) between acceleration hardware kernels with minimal CPU involvement. This also enables creation of large number of graph execution pipelines (streams) as needed for modern day edge-AI applications like video analytics (e.g. a Drone based surveillance system with 10+ AI models in parallel running on a cost effective SoC) enabling multi-kernel processing involving Neural Processing accelerators, Computer vision (CV) accelerators, Image signal processors, Video Codecs etc. This is extremely important for On-device and on-premise hardware AI analytics and for low-power embedded vision applications. Conventional architectures fail to meet the multi-kernel processing efficiency, which is key for Edge-AI system on chips for device market. This is a unique feature for Netrasemi’s SoCs making them ideal for smart cameras and other device mount systems. The architecture is also supported by a low code, no code software framework that helps the developers to use the architecture with ease, in porting their existing algorithms and AI models. And, achieve the best performance out of the hardware acceleration architecture with minimal errors and time.



Netrasemi has a UCIe (Universal chiplet Interconnect express) based D2D interconnect technology for multi-die extension of our Domain Specific Architecture (DSA). With the help of our DSA we have the capabilities to support wide range of edge applications extending our Netra-SOC compute capabilities. This include high TOPs (Upto 100 TOPS) neural chips and hybrid application processors for communication and other technology domains. Netrasemi is looking for partnerships to enable a chiplet based multi-die technology roadmap of our DSA through technology collaboration.

